文章目录
DETR:基于 Transformers 的目标检测
前言
最近可以说是随着 ViT 的大火,几乎可以说是一天就能看到一篇基于 Transformers 的 CV 论文,今天给大家介绍的是另一篇由 Facebook 在 ECCV2020 上发表的一篇基于 Transformers 的目标检测论文,这篇论文也是后续相当多的 Transformers 检测 / 分割的 baseline, 透过这篇论文我们来了解其套路.
相关工作
提到目标检测,我们先来简要回顾一下最基础的一个工作 Faster R-CNN
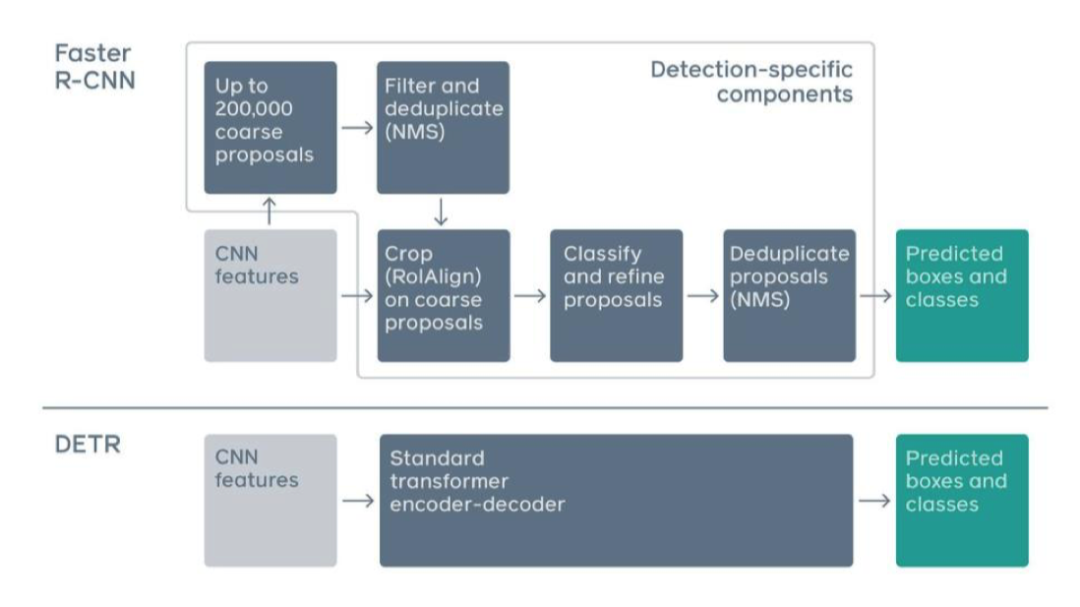
Faster R-CNN 第一步是用 CNN 给图像提特征,再通过非极大值抑制算法提取出候选框,最后预测每个候选框的位置和类别,
DETR 的实现原理
DETR 这篇文章就极大的简化了这个过程,他把候选框提取的过程通过一个标准的 Transformers encoder-decoder 架构代替,在 decoder 部分直接预测出来物体的位置和类别.
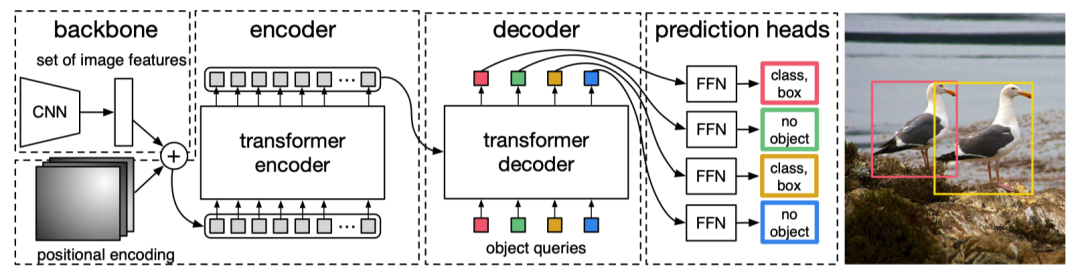
流程分为三步:
- CNN 提特征
- Transformers 的 encoder-decoder 进行信息的融合
- FFN 预测 class 和 box
CNN
利用 resnet-50 网络,将输入的图像 3 X W0 X H0 变成尺度为 2048 X W0/32 X H0/32 的特征,再通过一个 1X1 卷积,将 channel 从 2048 变为更小 (通常 512)
Transformers encoder-decoder
Transformer encoder 部分首先将输入的特征图降维并 flatten 成 d 个 H X W 维的向量,每个向量作为输入的 token, 由于 Self-attention 是置换不变形的,所以为了体现每个 token 在原图中的顺序关系,我们给每个 token 加上一个 positional encodings. 输出这是对应 Decoder 部分的 V 和 K.
比如说我们一开始输入的图片是 512*512, 那么 d 应该是 256.
Transformers decoder 部分是输入是 100 个 Object queries, 比如说我们数据集总共有 100 个类别的物体需要预测,那么这 100 object queries 经过 Transformers decoder 之后会预测出若干类别的物体和位置信息.
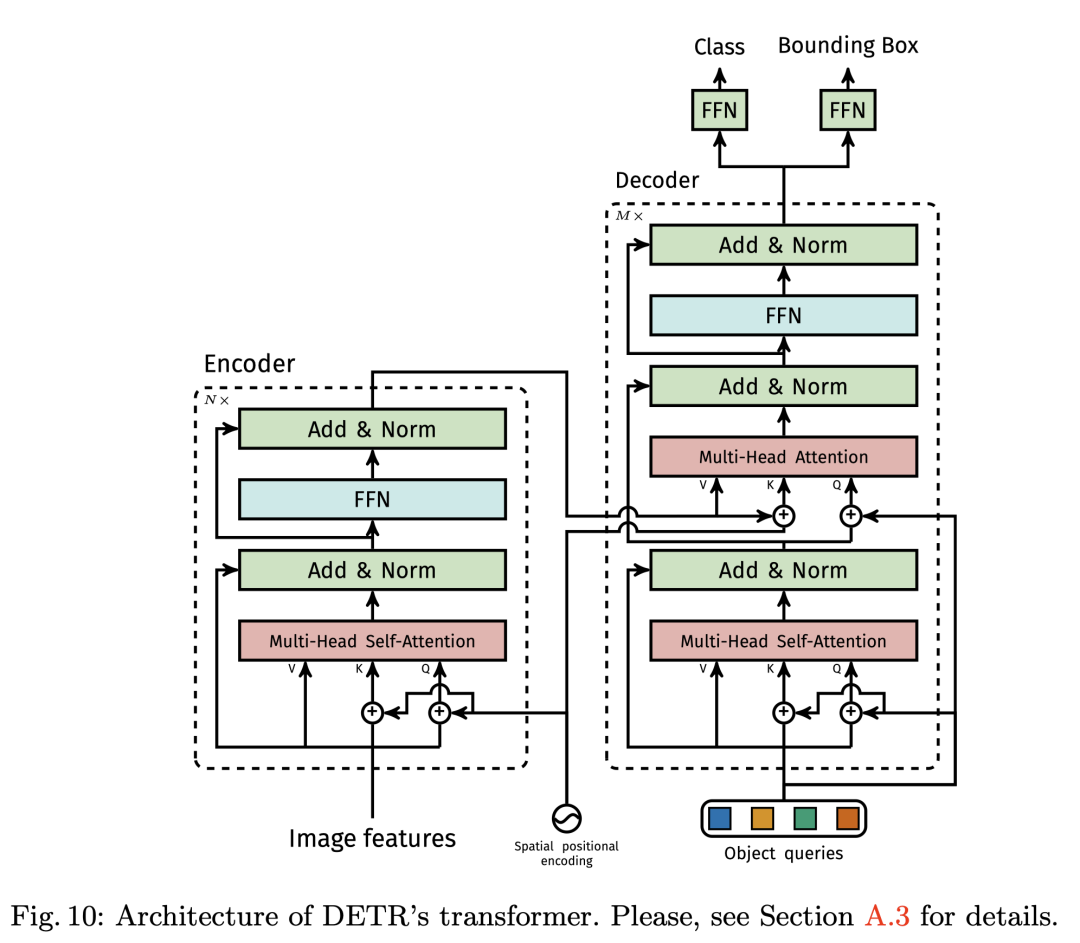
作者发现在训练过程中在 decoder 中使用 auxiliary losses 很有帮助,特别是有助于模型输出正确数量的每个类的对象。
FFN
DETR 在每个解码器层之后添加预测 FFN 和 Hungarian loss,所有预测 FFN 共享其参数。我们使用附加的共享层范数来标准化来自不同解码器层的预测 FFN 的输入,FFN 是一个最简单的多层感知机模块,对 Transformers decoder 的输出预测每个 object query 的类别和位置信息。在实际训练的过程中,通过匈牙利算法匹配预测和标签最小的损失,仅适用配对上的 query 计算 loss 回传梯度.
loss 包括 Box loss 和 class loss
Box Loss 包括 IOUloss 和 L1loss, 这个原理很简单.
where are hyperparameters and is the generalized IoU [38]:
class loss 就是最简单的交叉熵了.
匈牙利匹配
匈牙利匹配算法是离散数学中图论部分的一个经典算法,描述的问题是一个二分图的最大匹配。换成人话来说就是这个二分图分成两部分,一部分是我们对 100 种 object query 预测的结果,另一部分是实际的标签,由于我们一开始是不知道这 100 个 object query 输入的时候应该预测那些类别的物体,有可能一开始第一个 token 预测的是 A 物体,第二个 token 预测的是 C 物体,总而言之是无序的,我们就要根据实际的 label, 找到预测结果中和他最接近的计算 loss. 其他没匹配上的则不计算 loss 回传梯度。下面这张图一目了然:

通过对比 ViT 思考 DETR
其实笔者在阅读这篇文章的时候更加重点的是对比 ViT 在一些实现细节上的不同之处,
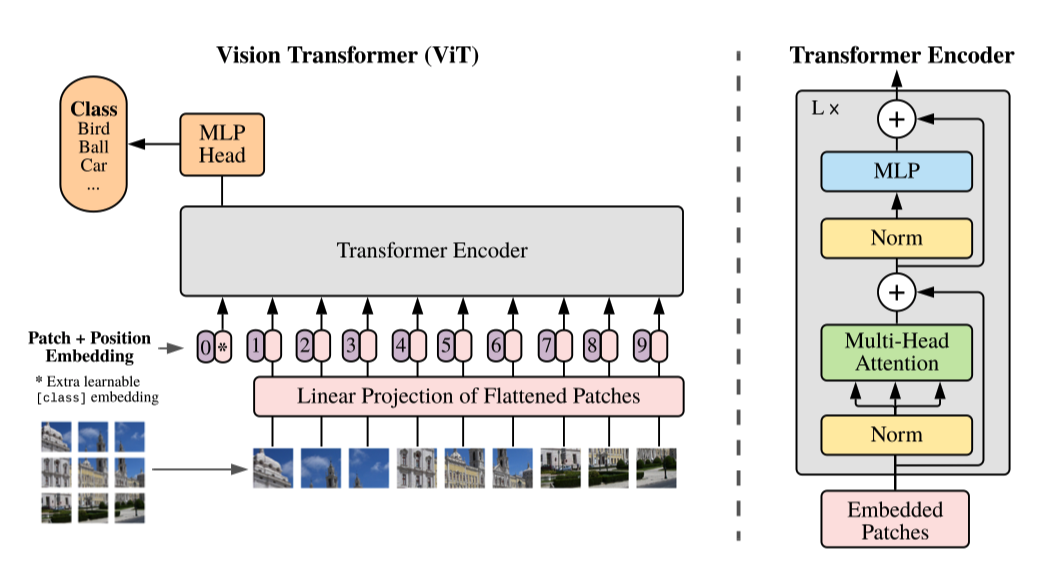
- 首先 ViT 是没有使用 CNN 的,而 DETR 是先用 CNN 提取了图像的特征
- ViT 只使用了 Transformers-encoder, 在 encoder 的时候额外添加了一个 Class token 来预测图像类型,而 DETR 的 object token 则是通过 Decoder 学习的.
- DETR 和 VIT 中的 Transformers 在 encoder 部分都使用了 Position Embedding, 但是使用的并不一样,而 VIT 在使用的 Position Embedding 也是笔者一开始阅读文献的疑惑所在.
- DETR 的 Transformers encoder 使用的 feature 的每一个 pixel 作为 token embeddings 输入,而 ViT 则是直接把图像切成 16*16 个 Patch, 每个 patch 直接拉平作为 token embeddings
- 相比较 VIT,DETR 更接近原始的 Transformers 架构.
DETR 还能做分割
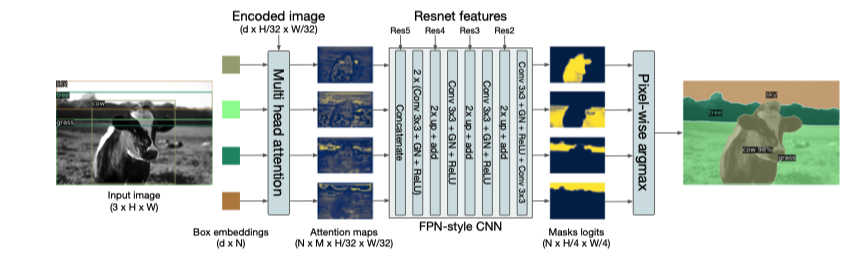
- 首先检测 box
- 对每个 box 做分割
- 为每个像素的类别投票
作者在这篇论文在并没有详细讲实现细节,但是今年 CVPR2021 上发表的 SETR 则是重点讲如何利用 Transformers 做分割,我们下次细讲.
实验结果分析
Comparison Study
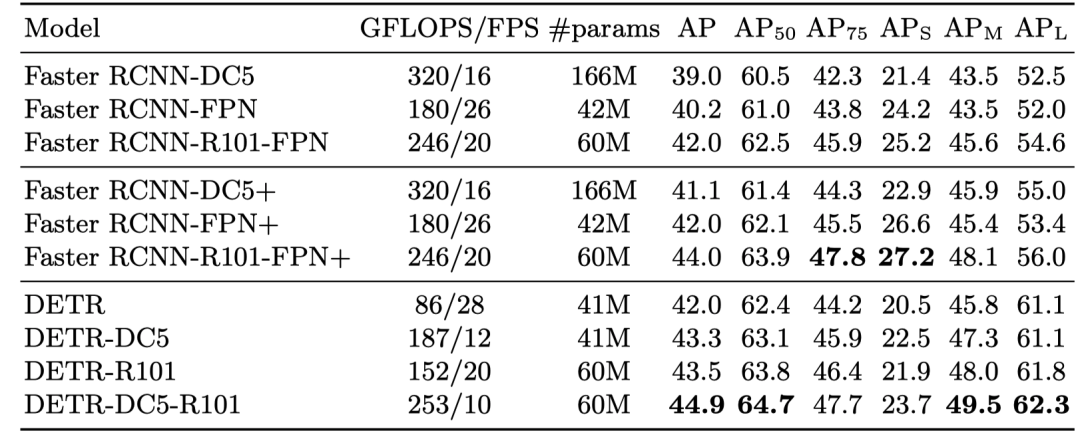
对比的是检测领域最经典的 Faster R-CNN, 可以看得出来了在同等参数两的情况下,在大目标物体的检测结果优于 Faster R-CNN, 道理嘛作者说是 Transformers 可以更关注全局信息.
Ablation Study

- Decoder 比 Encoder 重要
- Decoder 具有隐含的 “锚”,这对检测至关重要
- Encoder 仅帮助聚合同一对象的像素,减轻 decoder 的负担
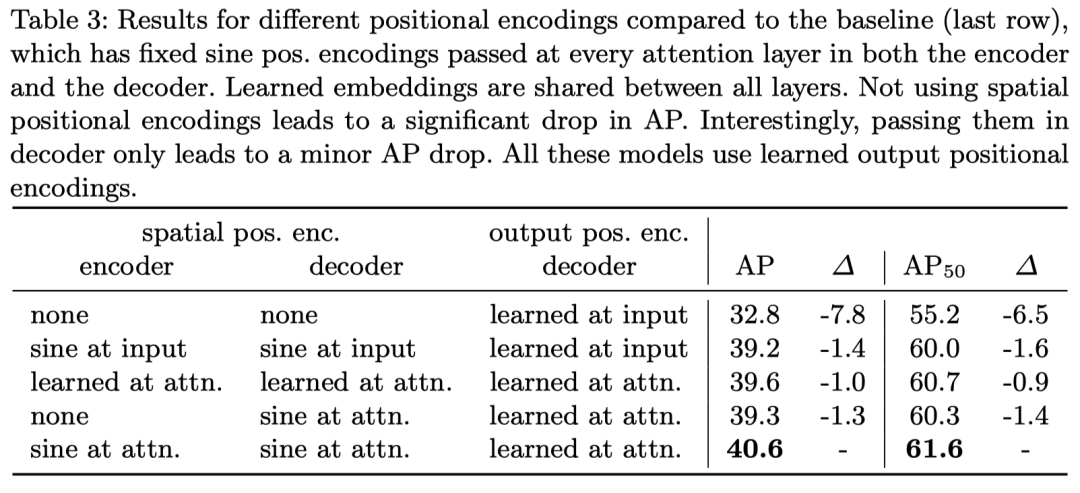
在位置编码部分,作者对比了可学习的位置编码和基于 Sincos 函数的位置编码方法 (也就是原始 Transformers 的位置编码方法) 可以看得出来效果是 Sincos 的更好,但是都显著好于不加位置编码,因为作者也在原文中 Self-Attention 是并行的,他如果不加位置编码的话是置换不变性的 (这个看 Attention is All you Need 原文)
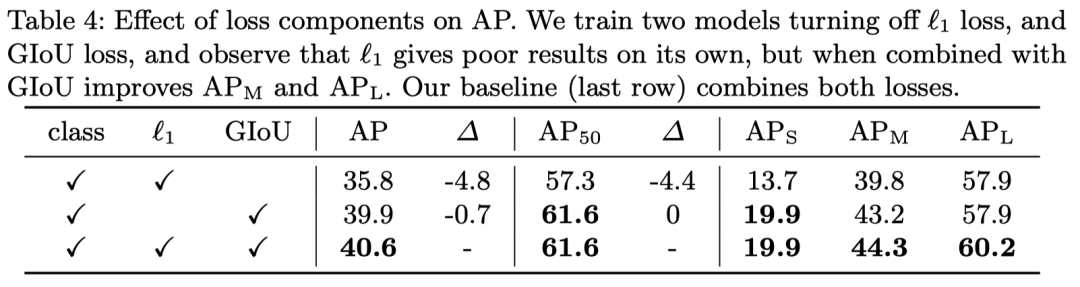
这个嘛,就是很简单的实验了,验证一下 loss 每个部分的作用,基本上就是格式化的东西.
简易代码
作者最后在附录部分贴上了简易的代码实现细节
1 | import torch |
结论
一篇很简单的 Transformers 在目标检测上的应用,也是最近大火的 Transformers 系列必引的一篇论文,我觉得他和 VIT 代表了 CV 对 Transformers 架构的两种看法吧,VIT 是只用 Encoder, 这也是目前最主流的做法,而 DETR 则是运用了 CNN 和 Transformers encoder-decoder 的结合,从 motivation 上来说我个人更喜欢 DETR, 这段时间也基本上把 Transformers 一系列都读完了,会以一个系列调几篇好的论文讲解 (水文实在是太多了)。
