文章目录
常见的 NLG 评估指标
引言
如何判定训练出来的模型好与坏呢?关键是要有一个比较好的模型评估方法,那么今天作者就给大家汇总一下自然语言生成(NLG)中经常见到的无监督自评估方法(BLEU、METEOR、ROUGE、CIDEr)(含评估代码)。
BLEU 评估法(机器翻译)
Bleu 全称为 Bilingual Evaluation Understudy(双语评估研究) ,意为双语评估替换,是 IBM 在 2002 年提出的用于机器翻译的一个评测指标,是衡量一个有多个正确输出结果的模型的精确度的评估指标。
BLEU 的设计思想与评判机器翻译好坏的思想是一致的:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU 算法实际上在做的事:判断两个句子的相似程度。我想知道一个句子翻译前后的表示是否意思一致,显然没法直接比较,那我就拿这个句子的标准人工翻译与我的机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。因此,BLUE 去做判断:一句机器翻译的话与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。
举个例子:下面拿中英机器翻译做例子:
中文:垫上有一只老鼠。
参考翻译 1:The cat is on the mat.
参考翻译 1:There is a cat on the mat.
MT (机器翻译):the cat the cat on the mat.
bleu 的得分有一元组,二元组,三元组等等,这里做了 1-3 元组的例子,如下:
下面先计算 BELU 一元组得分,即先把 MT 输出的句子拆分成 the,cat,on,mat,频数分别为 3,2,1,1:
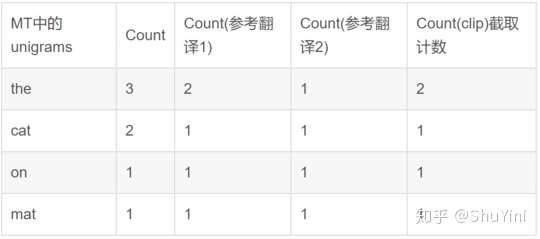
上面的 Count (clip) 叫截取计数,是取每个单词在所有参考翻译句子中,出现最多的次数,the 在参考翻译 1 中出现 2 次,在参考翻译 2 中出现 1 次,所以 the 的 Count (clip) 取最大值就是 2,剩下的单词依次类推。
所以 BLEU 的一元组上的得分为: p1 = Count (clip)/Count=(2+1+1+1)/(3+2+1+1) =5/7
下面再计算 BLEU 的二元组得分:
参考翻译 1:The cat is on the mat.
参考翻译 1:There is a cat on the mat.
MT (机器翻译):the cat the cat on the mat.
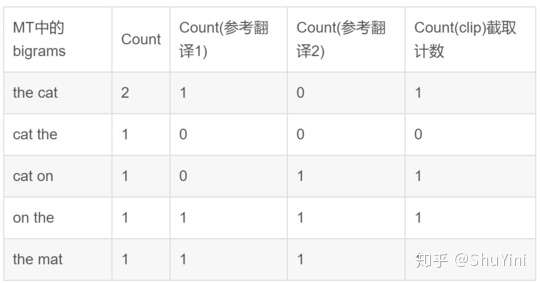
所以 bleu 的二元组的得分为:p2 = Count (clip)/Count=(1+0+1+1+1)/(2+1+1+1+1) =4/6=2/3
同理 BELU 的三元组得分:
参考翻译 1:The cat is on the mat.
参考翻译 1:There is a cat on the mat.
MT (机器翻译):the cat the cat on the mat.
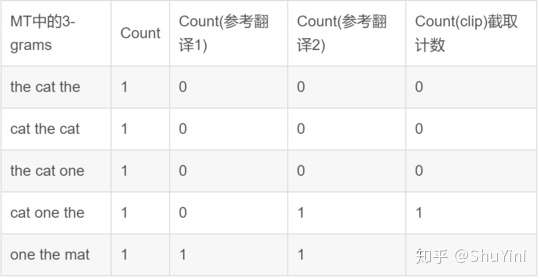
所以 bleu 的三元组的得分为:p3 = Count (clip)/Count= 2/5;最后加所有元组的 bleu 得分都加起来然后取平均数得: bleu(avg) = (p1+p2+p3)/3 = (5/7+2/3+2/5)/3 = 0.594
最后再乘上一个 “简短惩罚” BP(brevity penalty),即最后的 bleu 得分为:Bleu (total)=BP * bleu (avg)。
这里为什么要乘以 BP:如果 MT 输出了一个非常短的翻译,那么会更容易得到一个高精度的 bleu,因为输出的大部分词都会出现在参考翻译中,所以我们并不想要特别短的翻译结果,所以加入 BP 这么一个调整因子:
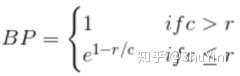
上式中,r 为参考翻译的句子长度,c 为 MT 的输出句子长度,若 c<=r , 则 0<exp (1-r/c)<=1, 得分 bleu (avg) 就会乘以小于 1 的系数 ,从而被 “惩罚”。 那么最后:Bleu (total)=BP*bleu (avg)
ROUGE 评估法(自动摘要)
Rouge (recall-oriented understanding for gisting evaluation) 是评估自动文摘以及机器翻译的一组指标。
论文链接地址:http://citeseer.ist.psu.edu/viewdoc/download
该方法的主要是思想是:由多个专家分别生成人工摘要,构成标准摘要集。将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n 元语法、词序列和词对)的数目,来评价摘要的质量。通过多专家人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现在已经成为摘要评价技术的通用标准之一。关于该算法演变评价标准有:Rouge-N、Rouge-L、Rouge-S、Rouge-W、Rouge-SU。
Rouge-N

其中,n 表示 n-gram 的长度,{Reference Summaries} 表示参考摘要,即事先获得的标准摘要,Countmatch (gramn) 表示候选摘要和参考摘要中同时出现 n-gram 的个数,Count (gramn) 则表示参考摘要中出现的 n-gram 个数。不难看出,ROUGE 公式是由召回率的计算公式演变而来的,分子可以看作 “检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的 N-gram 个数,分母可以看作 “相关文档数目”,即标准摘要中所有的 N-gram 个数。具体计算方式具体如下:

通过上面可以看到其实 ROUGE-N 和 BLEU 几乎一模一样,区别是 BLEU 只计算准确率,而 ROUGE 只计算召回率。
优点:直观,简介,能反映词序。
缺点:区分度不高,且当 N>3 时,ROUGE-N 值通常很小。
应用场景:ROUGE-1:短摘要评估,多文档摘要(去停用词条件);ROUGE-2: 单文档摘要,多文档摘要(去停用词条件);
Rouge-L
子序列:一个给定序列的子序列就是该给定序列中去掉零个或者多个元素。
公共子序列:给定两个序列 X 和 Y,如果 Z 既是 X 的一个子序列又是 Y 的一个子序列,则序列 Z 是 X 和 Y 的一个公共子序列。
LCS(最长公共子序列):给定两个序列 X 和 Y,使得公共子序列长度最大的序列是 X 和 Y 的最长公共子序列。其计算公式为:
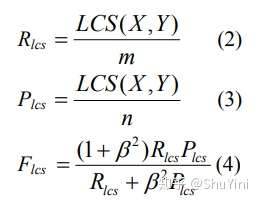
其中 X 为参考摘要,长度为 m,Y 为候选摘要,长度为 n,用 F 值来衡量摘要 X 与 Y 的相似度,在 DUC 测评中,由于 β—>+∞,所以只考虑 Rlcs 。具体计算例子如下:

优点:不要求词的连续匹配,只要求按词的出现顺序匹配即可,能够像 n-gram 一样反映句子级的词序。自动匹配最长公共子序列,不需要预先定义 n-gram 的长度。
缺点:只计算一个最长子序列,最终的值忽略了其他备选的最长子序列及较短子序列的影响。
应用场景:单文档摘要;短摘要评估。

将 LCS 应用到摘要级数相时,对参考摘要中的每一个句子 *ri 与候选摘要中的所有句子比对,以 union LCS 作为摘要句 ri * 的匹配结果。计算公式:
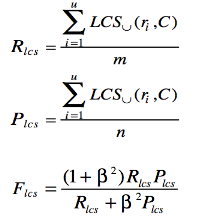
其中 R 为参考摘要,包含 u 个句子,m 个词,C 为候选摘要,包含 v 个句子,n 个词,长度为 n,LCSU(ri,C) 是句子 ri 和候选摘要 C 的 union LCS。

Rouge-W
为使连续匹配比不连续匹配赋予更大的权重,公式描述如下:
例如 f(k) = kα,α>1 ,同时为了归一化最终的 Rouge-W 的值,通常选择函数与反函数具有相似形式的函数。例如: f(k) = k2, f-1 = k1/2 ,具体计算公式如下所示:
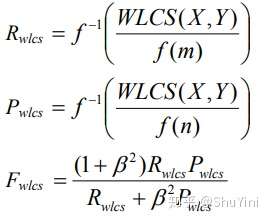
举个例子如下:

优点:同一 LCS 下,对连续匹配词数多的句子赋予更高权重,比 LCS 区分度更高。
缺点:同 ROUGE-L,只计算一个最长子序列,最终的值忽略了其他备选的最长子序列及较短子序列的影响。
应用场景:单文档摘要;短摘要评估。
Rouge-S
Skip-Bigram 是按句子顺序中的任何成对词语。计算公式如下:
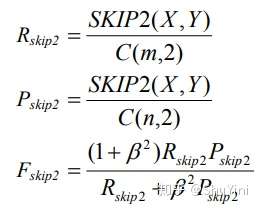
其中 X 为参考摘要,长度为 m,Y 为候选摘要,长度为 n。SKIP2 (X,Y) 表示候选摘要与参考摘要的 skip-bigram 匹配次数。
Skip-gram 如果不限制跳跃的距离,会出现很多无意义的词对,比如 “the of”、“in the” 等。为了减少无意义词对的出现,可以限制最大跳跃距离 dskip,通常写 ROUGE-S4 表示最大跳跃距离为 4,ROUGE-S9 表示最大跳跃距离为 9,依次类推。如果 dskip 为 0,那么 ROUGE-S0 = ROUGE-2。举个例子如下:

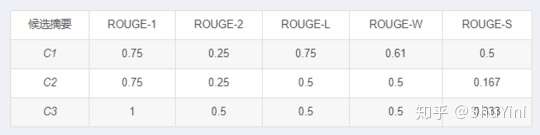
优点:考虑了所有按词序排列的词对,比 n-gram 模型更深入反映句子级词序。
缺点:若不设定最大跳跃词数会出现很多无意义词对。若设定最大跳跃词数,需要指定最大跳跃词数的值。
应用场景:单文档摘要;ROUGE-S4,ROUGE-S9: 多文档摘要(去停用词条件)。
METEOR 评估法(机器翻译、自动文摘)
2004 年,卡内基梅隆大学的 Lavir 提出评价指标中召回率的意义,基于此研究,Banerjee 和 Lavie(Banerjee and Lavie, 2005)发明了基于单精度的加权调和平均数和单字召回率的 METEOR 度量方法,目的是解决 BLEU 标准中的一些固有缺陷。
论文链接地址:http://www.cs.cmu.edu/~alavie/METEOR/pdf/Banerjee-Lavie-2005-METEOR.pdf
METEOR 扩展了 BLEU 有关 “共现” 的概念,提出了三个统计共现次数的模块:一是 “绝对” 模块(“exact” module),即统计待测译文与参考译文中绝对一致单词的共现次数;二是 “波特词干” 模块(porter stem module),即基于波特词干算法计算待测译文与参考译文中词干相同的词语 “变体” 的共现次数,如 happy 和 happiness 将在此模块中被认定为共现词;三是 “WN 同义词” 模块(WN synonymy module),即基于 WordNet 词典匹配待测译文与参考译文中的同义词,计入共现次数,如 sunlight 与 sunshine。
同时 METEOR 将词序纳入评估范畴,设立基于词序变化的罚分机制,当待测译文词序与参考译文不同时,进行适当的罚分。最终基于共现次数计算准确率、召回率与 F 值,并考虑罚分最终得到待测译文的 METEOR 值。
该算法首先计算 unigram 情况下的准确率 P 和召回率 R(计算方式与 BLEU、ROUGE 类似),得到调和均值 F 值:
看到这可能还没有什么特别的。Meteor 的特别之处在于,它不希望生成很 “碎” 的译文:比如参考译文是 “A B C D”,模型给出的译文是 “B A D C”,虽然每个 unigram 都对应上了,但是会受到很严重的惩罚。惩罚因子的计算方式为:
上式中的 chunks 表示匹配上的语块个数,如果模型生成的译文很碎的话,语块个数会非常多;unigrams_matched 表示匹配上的 unigram 个数。所以最终的评分为:
用于机器翻译评测时,通常取 α = 3,γ = 0.5,θ = 3。
自从 2004 年以来,该团队也在不断的对 METEOR 评估方法进行优化,具体可见:http://www.cs.cmu.edu/~alavie/METEOR/index.html
CIDEr 评价方法
CIDEr(Consensuus-based Image Description Evaluation)评价标准是 Vedantm 在 2015 年计算机视觉与模式识别大会上提出来的针对图像摘要问题的度量标准。
论文链接地址为:https://arxiv.org/pdf/1411.5726.pdf
研究者认为过去的多种评价方法和人类评价具有较强的相关性,但是无法统一到一个度量标准来评价与人的相似性(human-like),为了解决这个问题,从而评价计算机自动生成的句子到底有多像人工书写的,Vedantam 等人提出了基于共识的评价标准(consensus-based protocol),其基本工作原理就是通过度量带测评语句与其他大部分人工描述句之间的相似性来评价相似性。研究者证明 CIDEr 在与人工共识的匹配度上要好于前述其它评价指标。
CIDEr 首先将 n-grams 在参考句子中的出现频率编码进来,n-gram 在数据集所有图片中经常出现的图片的权重应该减少,因为其包含的信息量更少,该权重研究者通过 TF-IDF 计算每个 n-gram 的权重。将句子用 n-gram 表示成向量形式,每个参考句和待评测句之间通过计算 TF-IDF 项链的余玄距离来度量其相似性。
最后更新: 2021年08月08日 18:33
