文章目录
作者:动力节点在线
链接:https://www.zhihu.com/question/333417513/answer/742465814
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、Hadoop 是什么
1.1、小故事版本的解释
小明接到一个任务:计算一个 100M 的文本文件中的单词的个数,这个文本文件有若干行,每行有若干个单词,每行的单词与单词之间都是以空格键分开的。对于处理这种 100M 量级数据的计算任务,小明感觉很轻松。他首先把这个 100M 的文件拷贝到自己的电脑上,然后写了个计算程序在他的计算机上执行后顺利输出了结果。
后来,小明接到了另外一个任务,计算一个 1T(1024G)的文本文件中的单词的个数。再后来,小明又接到一个任务,计算一个 1P (1024T) 的文本文件中的单词的个数……
面对这样大规模的数据,小明的那一台计算机已经存储不下了,也计算不了这样大的数据文件中到底有多少个单词了。机智的小明上网百度了一下,他在百度的输入框中写下了:大数据存储和计算怎么办?按下回车键之后,出现了有关 Hadoop 的网页。
看了很多网页之后,小明总结一句话:Hadoop 就是存储海量数据和分析海量数据的工具。
1.2、稍专业点的解释
Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是 HDFS 与 MapReduce。
HDFS 是一个分布式文件系统:引入存放文件元数据信息的服务器 Namenode 和实际存放数据的服务器 Datanode,对数据进行分布式储存和读取。
MapReduce 是一个计算框架:MapReduce 的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map 计算 / Reduce 计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
1.3、记住下面的话
Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
把 HDFS 理解为一个分布式的,有冗余备份的,可以动态扩展的用来存储大规模数据的大硬盘。
把 MapReduce 理解成为一个计算引擎,按照 MapReduce 的规则编写 Map 计算 / Reduce 计算的程序,可以完成计算任务。
2、Hadoop 能干什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL: 数据抽取到 oracle、mysql、DB2、mongdb 及主流数据库
机器学习:比如 Apache Mahout 项目
搜索引擎:Hadoop + lucene 实现
数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop 是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
实际应用:
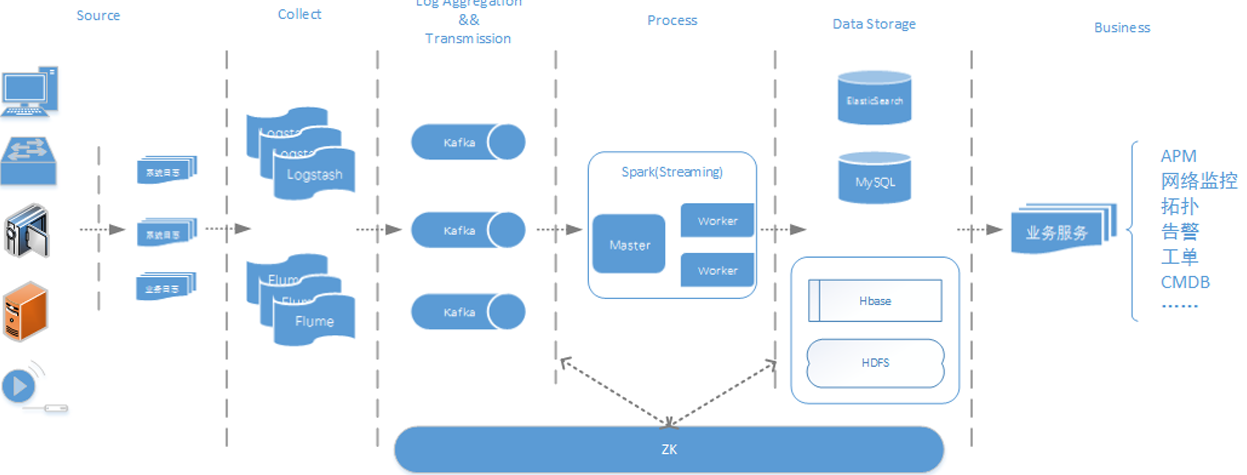
(1)Flume+Logstash+Kafka+Spark Streaming 进行实时日志处理分析
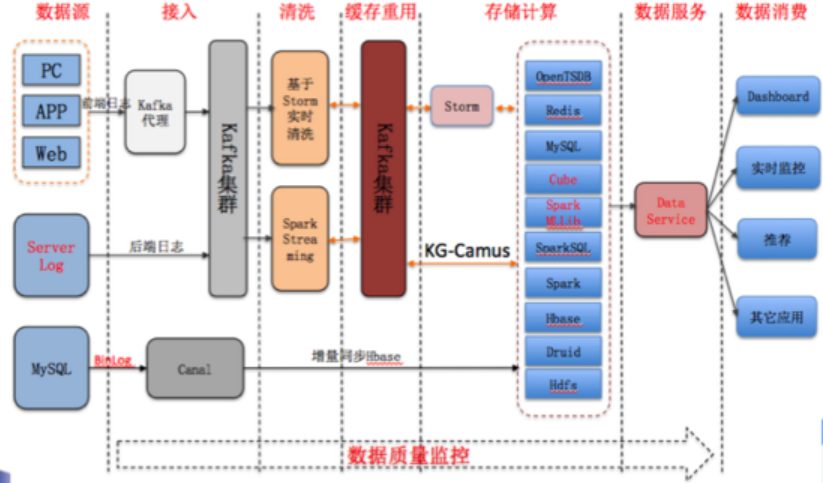
(2)酷狗音乐的大数据平台
3、怎么使用 Hadoop
3.1、Hadoop 集群的搭建
无论是在 windows 上装几台虚拟机玩 Hadoop,还是真实的服务器来玩,说简单点就是把 Hadoop 的安装包放在每一台服务器上,改改配置,启动就完成了 Hadoop 集群的搭建。
3.2、上传文件到 Hadoop 集群
Hadoop 集群搭建好以后,可以通过 web 页面查看集群的情况,还可以通过 Hadoop 命令来上传文件到 hdfs 集群,通过 Hadoop 命令在 hdfs 集群上建立目录,通过 Hadoop 命令删除集群上的文件等等。
3.3、编写 map/reduce 程序
通过集成开发工具(例如 eclipse)导入 Hadoop 相关的 jar 包,编写 map/reduce 程序,将程序打成 jar 包扔在集群上执行,运行后出计算结果。
最后更新: 2021年08月09日 14:01
原始链接: https://leezhao415.github.io/2021/08/09/Hadoop%E8%AF%A6%E8%A7%A3/
